library(tidyverse)
library(questionr)
data(hdv2003)
data(rp2018)
data(starwars)20 Débuggage et performance
20.1 Débugguer une fonction
Lorsqu’on commence à écrire des fonctions un peu complexes, avec des if, des for, et autres joyeusetés, arrive forcément un moment où ça ne fonctionne pas comme on le souhaiterait et où on ne comprend pas pourquoi. Bref, il y a un bug.
Trouver la cause d’un bug n’est pas toujours évident, mais il existe plusieurs méthodes et outils permettant de faciliter un peu les choses.
On commence par charger les extensions et les jeux de données dont on aura besoin par la suite.
20.1.1 print()
L’outil le plus simple, rudimentaire et parfois décrié mais qui reste efficace, est de rajouter un print() dans le code de notre fonction pour examiner le contenu d’un objet à un moment donné.
Prenons un exemple. La fonction suivante prend en argument un tableau de données df et un nom de variable var, et retourne la moyenne et l’écart-type de cette variable.
indicateurs <- function(df, var) {
valeurs <- df[, var]
if (!is.numeric(valeurs)) return(NA)
list(
moyenne = mean(valeurs, na.rm = TRUE),
sd = sd(valeurs, na.rm = TRUE)
)
}On teste notre fonction sur une variable du jeu de données hdv2003. Tout semble fonctionner.
indicateurs(hdv2003, "age")
#> $moyenne
#> [1] 48.157
#>
#> $sd
#> [1] 16.94181On teste à nouveau, cette fois sur une variable du jeu de données starwars de dplyr.
indicateurs(starwars, "height")
#> [1] NASapristi, on obtient NA en résultat alors que notre variable height est bien numérique : on devrait donc obtenir la moyenne et l’écart-type. Comment expliquer ce résultat ?
Comme on n’a pas d’explication immédiate juste en relisant le code de notre fonction, on va ajouter temporairement une instruction print() qui va afficher le contenu de valeurs juste après qu’elle soit calculée.
indicateurs <- function(df, var) {
valeurs <- df[, var]
print(valeurs)
if (!is.numeric(valeurs)) return(NA)
list(
moyenne = mean(valeurs, na.rm = TRUE),
sd = sd(valeurs, na.rm = TRUE)
)
}On lance cette fonction modifiée sur starwars :
indicateurs(starwars, "height")
#> # A tibble: 87 × 1
#> height
#> <int>
#> 1 172
#> 2 167
#> 3 96
#> 4 202
#> 5 150
#> 6 178
#> 7 165
#> 8 97
#> 9 183
#> 10 182
#> # ℹ 77 more rows
#> [1] NALe print() nous indique que valeurs n’est pas un vecteur mais un tableau de données à une seule colonne. Or dans ce cas, le test is.numeric, qui est sensé s’appliquer à un vecteur atomique, renvoie FALSE.
is.numeric(starwars[, "height"])
#> [1] FALSEC’est donc la raison pour laquelle on obtient NA comme résultat.
Certes, mais alors pourquoi cela fonctionne-t-il dans notre exemple avec hdv2003 ?
indicateurs(hdv2003, "age")
#> [1] 28 23 59 34 71 35 60 47 20 28 65 47 63 67 76 49 62 20 70 39 30 30 37 79 20
#> [26] 74 31 35 35 30 54 29 49 59 41 41 53 19 77 56 54 35 40 62 68 77 39 57 43 34
#> [51] 60 41 54 23 26 23 74 60 23 57 55 71 39 56 54 27 40 42 44 41 30 48 59 46 33
#> [76] 70 67 75 22 51 41 53 70 79 31 34 72 59 63 77 48 25 62 23 66 90 43 32 54 19
#> [101] 61 57 54 31 33 86 84 74 49 47 25 52 71 56 58 66 70 51 54 73 35 64 51 68 42
#> [126] 49 55 49 60 71 75 36 78 19 23 81 41 58 37 49 55 51 58 29 47 78 31 55 42 35
#> [151] 50 78 56 40 35 46 50 69 73 32 38 18 43 62 35 28 51 65 47 66 48 27 71 38 61
#> [176] 39 69 79 57 64 59 47 24 54 50 32 60 57 50 23 48 49 70 27 52 19 54 45 64 71
#> [ reached getOption("max.print") -- omitted 1800 entries ]
#> $moyenne
#> [1] 48.157
#>
#> $sd
#> [1] 16.94181Ah ! Dans ce cas là valeurs est bien un vecteur, et on obtient donc le résultat attendu. Pourquoi cette différence ? On est en fait tombé sur une différence de comportement entre les data frames et les tibbles, mentionnée Section 16.3.3 : lorsqu’on sélectionne une seule colonne avec l’opérateur [,], un data frame retourne un vecteur tandis qu’un tibble retourne un tableau à une colonne. Or, ici, hdv2003 est un data frame, et starwars un tibble.
Comment résoudre ce problème ? Il y a différentes manières, mais la plus simple est sans doute de remplacer [,] par [[]], qui lui a le même comportement dans les deux cas. On peut donc modifier notre fonction (en n’oubliant pas d’enlever le print()) et vérifier que ça fonctionne désormais.
indicateurs <- function(df, var) {
valeurs <- df[[var]]
if (!is.numeric(valeurs)) return(NA)
list(
moyenne = mean(valeurs, na.rm = TRUE),
sd = sd(valeurs, na.rm = TRUE)
)
}
indicateurs(hdv2003, "age")
#> $moyenne
#> [1] 48.157
#>
#> $sd
#> [1] 16.94181
indicateurs(starwars, "height")
#> $moyenne
#> [1] 174.6049
#>
#> $sd
#> [1] 34.77416
Avertissement
Quand on ajoute des print() pour essayer d’identifier un problème, il faut bien penser à les supprimer une fois ce problème résolu, sinon on risque de se retrouver avec des messages “parasites” dans la console.
20.1.2 Localiser une erreur
print() peut aussi être utile pour savoir à quel moment une erreur se produit, notamment lorsqu’on utilise une boucle.
Dans l’exemple suivant, on crée une fonction min_freq_values() qui prend en argument un tableau de données df et un effectif n_min et retourne une liste des modalités de variables qui apparaissent dans au moins n_min lignes de df (on utilise ici une boucle for, mais on aurait aussi pu utiliser map()).
min_freq_values <- function(df, n_min) {
res <- list()
for (col in names(df)) {
# Tri à plat des valeurs de la colonne
freq <- table(df[[col]])
# On conserve les modalités avec effectif >= n
freq <- freq[freq >= n_min]
# On ajoute la colonne au résultat s'il y a au moins une modalité
if (length(freq) > 0) res[[col]] <- freq
}
res
}Si on applique min_freq_values() à hdv2003 avec une valeur de n à 1500, on obtient toutes les modalités correspondant à au moins 1500 observations.
min_freq_values(hdv2003, 1500)
#> $hard.rock
#> Non
#> 1986
#>
#> $lecture.bd
#> Non
#> 1953
#>
#> $peche.chasse
#> Non
#> 1776Essayons maintenant d’appliquer min_freq_values() au jeu de données starwars de dplyr.
min_freq_values(starwars, 50)
#> Error in table(df[[col]]): all arguments must have the same lengthOn obtient un message quelque peu sybillin : apparemment une erreur se produit au moment de faire le tri à plat des valeurs avec table(). Mais comme ce tri à plat s’effectue dans une boucle, on ne sait pas quelle variable de starwars est à l’origine du problème.
On va donc rajouter un print(col) comme première instruction de la boucle for.
min_freq_values <- function(df, n_min) {
res <- list()
for (col in names(df)) {
print(col)
# Tri à plat des valeurs de la colonne
freq <- table(df[[col]])
# On conserve les modalités avec effectif >= n
freq <- freq[freq >= n_min]
# On ajoute la colonne au résultat s'il y a au moins une modalité
if (length(freq) > 0) res[[col]] <- freq
}
res
}
min_freq_values(starwars, 50)
#> [1] "name"
#> [1] "height"
#> [1] "mass"
#> [1] "hair_color"
#> [1] "skin_color"
#> [1] "eye_color"
#> [1] "birth_year"
#> [1] "sex"
#> [1] "gender"
#> [1] "homeworld"
#> [1] "species"
#> [1] "films"
#> Error in table(df[[col]]): all arguments must have the same lengthCe print(col) nous permet de voir que tout se passe bien pour les premières variables du tableau, et que l’erreur survient au moment de traiter la variable films. On regarde donc à quoi ressemble cette variable.
head(starwars$films, 3)
#> [[1]]
#> [1] "A New Hope" "The Empire Strikes Back"
#> [3] "Return of the Jedi" "Revenge of the Sith"
#> [5] "The Force Awakens"
#>
#> [[2]]
#> [1] "A New Hope" "The Empire Strikes Back"
#> [3] "Return of the Jedi" "The Phantom Menace"
#> [5] "Attack of the Clones" "Revenge of the Sith"
#>
#> [[3]]
#> [1] "A New Hope" "The Empire Strikes Back"
#> [3] "Return of the Jedi" "The Phantom Menace"
#> [5] "Attack of the Clones" "Revenge of the Sith"
#> [7] "The Force Awakens"Damn, cette variable n’est pas un vecteur atomique mais une liste ! Un tableau de données peut en effet contenir ce que l’on appelle des colonnes-listes. Comme ça n’est pas courant, on ne l’avait clairement pas prévu au moment de la création de la fonction.
On a désormais identifié le problème, on peut donc le corriger par exemple en ignorant les colonnes de type liste. Pour cela on utilise is.list() et l’instruction next.
min_freq_values <- function(df, n_min) {
res <- list()
for (col in names(df)) {
# On passe à la colonne suivante si la colonne est une colonne-liste
if (is.list(df[[col]])) next
# Tri à plat des valeurs de la colonne
freq <- table(df[[col]])
# On conserve les modalités avec effectif >= n
freq <- freq[freq >= n_min]
# On ajoute la colonne au résultat s'il y a au moins une modalité
if (length(freq) > 0) res[[col]] <- freq
}
res
}
min_freq_values(starwars, 50)
#> $sex
#> male
#> 60
#>
#> $gender
#> masculine
#> 66Ça fonctionne ! Et cela nous permet de repérer au passage une “légère” sur-représentation des personnages masculins…
20.1.3 browser()
Il existe des alternatives à print() plus efficaces pour identifier et résoudre des bugs. La plus utilisée est la fonction browser() : celle-ci peut s’insérer à n’importe quel endroit du code, et lorsqu’elle est rencontrée par R celui-ci s’interrompt et affiche une invite de commande permettant notamment d’inspecter des objets.
On reprend l’exemple précédent en remplaçant le print(col) que nous avions inséré pour débugguer la fonction min_freq_values par un appel à browser().
min_freq_values <- function(df, n_min) {
res <- list()
for (col in names(df)) {
browser()
# Tri à plat des valeurs de la colonne
freq <- table(df[[col]])
# On conserve les modalités avec effectif >= n
freq <- freq[freq >= n_min]
# On ajoute la colonne au résultat s'il y a au moins une modalité
if (length(freq) > 0) res[[col]] <- freq
}
res
}
min_freq_values(starwars, 50)Lorsqu’on lance ce code, R s’interrompt et affiche l’invite de commande suivant :
Called from: min_freq_values(starwars, 50)
Browse[1]>Cette invite de commande offre plusieurs possibilités. La première est d’indiquer du code R qui sera exécuté dans le contexte au moment de l’interruption : si on indique un nom d’objet, on pourra donc afficher sa valeur. Ainsi, si on tape col, R nous affiche la valeur actuelle de col, donc au moment de la première itération de la boucle.
Browse[1]> col
[1] "name"On peut également fournir des commandes spécifiques : si on tape n, R va passer à l’instruction suivante puis s’interrompre à nouveau1.
Browse[1]> n
debug à #6 : freq <- table(df[[col]])Si on tape c, R va relancer l’exécution jusqu’à la fin, ou jusqu’à la prochaine rencontre d’un browser(). Dans notre cas, cela signifie qu’on va continuer jusqu’au browser() de la deuxième itération de la boucle.
Browse[2]> c
Called from: min_freq_values(starwars, 50)
Browse[1]> col
[1] "height"Si on souhaite sortir de cette invite de commande et tout interrompre, il suffit de taper Q.
browser() est donc un peu plus complexe à utiliser que des print() ajoutés manuellement, mais c’est aussi un outil plus souple et plus puissant.
Note
Cette section n’offre qu’un petit aperçu des possibilités de débuggage. R propose d’autres fonctionnalités, et les environnements de développement comme RStudio ou Visual Studio Code proposent également leurs propres outils.
Pour plus d’informations on pourra se reporter aux ressources en fin de chapitre.
20.2 benchmarking : mesurer et comparer les temps d’exécution
Lorsqu’on commence à créer ses propres fonctions et de manière générale à écrire du code de plus en plus complexe ou à travailler sur des données de plus en plus volumineuses, on peut arriver sur des problèmes de performance : les temps d’exécution deviennent longs et on aimerait essayer de les optimiser.
Il est alors parfois utile de faire du benchmarking, c’est-à-dire comparer plusieurs manières différentes de faire la même chose en mesurant leurs différences de vitesse d’exécution.
L’intruction la plus simple pour cela est sans doute system.time(). Celle-ci prend en argument une expression R, et affiche en retour le temps d’exécution en secondes.
system.time(runif(1000000))
#> user system elapsed
#> 0.008 0.002 0.009L’expression peut comporter plusieurs instructions, dans ce cas on les entoure d’accolades.
system.time({
v <- runif(1000000)
moy <- mean(v)
})
#> user system elapsed
#> 0.011 0.002 0.014system.time() est cependant très limitée : on ne peut exécuter qu’une expression à la fois, on ne peut donc pas en comparer plusieurs directement, et surtout le temps d’exécution peut varier assez sensiblement selon l’utilisation du processeur de la machine au moment où on lance la commande.
Il existe donc en complément plusieurs extensions dédiées au benchmarking. On va utiliser ici l’extension bench, installable avec :
install.packages("bench")bench propose une fonction principale, nommée mark(), qu’on peut donc appeler directement avec bench::mark()2. On passe à cette fonction plusieurs expressions, et bench::mark() va effectuer les actions suivante :
- elle vérifie que les expressions retournent bien le même résultat (si on souhaite comparer des expressions qui renvoient des résultats différents, il faut ajouter l’argument
check = FALSE) - elle lance chacune de ces expressions plusieurs fois et mesure à chaque fois leur temps d’exécution
- elle affiche un résumé de ces temps d’exécution en indiquant notamment leur minimum et leur médiane
Exécuter chaque expression plusieurs fois permet de prendre en compte les fluctuations liées à l’activité du processeur de la machine. Par défaut, bench::mark() exécute chaque instruction au minimum une fois et au moins suffisamment de fois pour atteindre 0,5s d’exécution (ces valeurs peuvent être modifiées via les paramètres min_iterations et min_time).
Dans l’exemple suivant, on crée deux fonctions qui font la même chose : ajouter 10 à tous les éléments d’un vecteur passé en argument. Dans la première fonction plus10_for on utilise une boucle for qui ajoute 10 à tous les éléments l’un après l’autre (ce qu’il ne faut évidemment pas faire !), tandis que la deuxième fonction plus10_vec utilise la forme vectorisée x + 10.
plus10_for <- function(x) {
for (i in seq_along(x)) {
x[i] <- x[i] + 10
}
x
}
plus10_vec <- function(x) {
x + 10
}On lance un benchmark avec bench::mark() et on stocke le résultat dans un objet.
x <- 1:10000
bnch <- bench::mark(
plus10_for(x),
plus10_vec(x)
)On affiche les résultats obtenus :
bnch
#> # A tibble: 2 × 6
#> expression min median `itr/sec` mem_alloc `gc/sec`
#> <bch:expr> <bch:tm> <bch:tm> <dbl> <bch:byt> <dbl>
#> 1 plus10_for(x) 536.66µs 562.9µs 1766. 96.7KB 4.07
#> 2 plus10_vec(x) 9.96µs 11.8µs 82688. 117.3KB 174.La colonne la plus importante est sans doute la colonne median, qui affiche le temps médian d’exécution des deux expressions. Attention, l’unité de temps n’est pas forcément la même, ici l’exécution de plus10_for est affichée en millisecondes (“ms”), tandis que celle de plus10_vec l’est en microsecondes (“µs”) donc avec une unité mille fois plus petite.
Si on préfère, on peut afficher les performances relatives des deux fonctions avec :
summary(bnch, relative = TRUE)
#> # A tibble: 2 × 6
#> expression min median `itr/sec` mem_alloc `gc/sec`
#> <bch:expr> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 plus10_for(x) 53.9 47.6 1 1 1
#> 2 plus10_vec(x) 1 1 46.8 1.21 42.8Ces résultats nous permettent de voir que la version vec est très nettement plus rapide que la version for ! Ce qui confirme le fait qu’il faut toujours prioriser l’utilisation de fonctions vectorisées lorsqu’elles existent.
On prend un second exemple : on souhaite mesurer si l’utilisation de map est plus rapide ou non qu’une boucle for pour une tâche équivalente.
Pour cela on commence par créer artificiellement une liste de 200 tableaux de données en dupliquant 100 fois une liste composée des tableaux rp2018 et hdv2003.
dfs <- list(rp2018, hdv2003)
dfs <- rep(dfs, 100)Puis on lance un benchmark sur une boucle for et un map qui retournent chacun les nombres de ligne des 200 tableaux. Cette-fois on ne crée pas de fonctions : on passe le code directement à bench::mark(), avec des noms permettant de les identifier plus facilement dans les résultats.
bench::mark(
boucle_for = {
res <- list()
for (df in dfs) {
res <- c(res, nrow(df))
}
res
},
map = map(dfs, ~ nrow(.x) )
)
#> # A tibble: 2 × 6
#> expression min median `itr/sec` mem_alloc `gc/sec`
#> <bch:expr> <bch:tm> <bch:tm> <dbl> <bch:byt> <dbl>
#> 1 boucle_for 2.33ms 2.38ms 418. 198.94KB 10.7
#> 2 map 746.5µs 783.56µs 1269. 6.71KB 12.5La lecture du résultat indique que le map est environ 4 fois plus rapide que la boucle for.
Attention cependant en lisant ces résultats : dans la comparaison précédente les temps d’exécution étant en millisecondes, même une différence du type “4 fois plus rapide” peut être quasiment imperceptible. Dans l’exemple suivant on compare de la même manière for et map, mais cette fois en effectuant une action plus coûteuse en temps de calcul (on génère des vecteurs de nombres aléatoires).
bench::mark(
boucle_for = {
res <- numeric()
for (i in 1:100) {
res <- c(res, mean(runif(50000)))
}
res
},
map = map_dbl(1:100, ~ mean(runif(50000))),
check = FALSE
)
#> # A tibble: 2 × 6
#> expression min median `itr/sec` mem_alloc `gc/sec`
#> <bch:expr> <bch:tm> <bch:tm> <dbl> <bch:byt> <dbl>
#> 1 boucle_for 78.8ms 79ms 12.7 38.2MB 0
#> 2 map 76.8ms 77ms 12.8 38.2MB 2.14Dans ce cas la différence entre for et map devient négligeable par rapport aux temps de calcul des opérations effectuées dans les boucles : au final les temps d’exécution sont presque identiques.
20.3 Quelques conseils d’optimisation
20.3.1 Privilégier les fonctions vectorisées
On l’a déjà dit, redit et reredit, une des forces de R est de proposer un grand nombre de fonctions vectorisées, c’est-à-dire prévues et optimisées pour s’appliquer à tous les éléments d’un vecteur. Quand une fonction vectorisée existe, il est donc toujours préférable de l’utiliser plutôt qu’une boucle ou un map.
v <- rep(c("Pomme", "Poire", "Fraise"), 100)
bench::mark(
boucle = {
map_int(v, str_count, "m")
},
vec = str_count(v, "m")
)
#> # A tibble: 2 × 6
#> expression min median `itr/sec` mem_alloc `gc/sec`
#> <bch:expr> <bch:tm> <bch:tm> <dbl> <bch:byt> <dbl>
#> 1 boucle 3.72ms 3.82ms 258. 112.38KB 8.53
#> 2 vec 44.53µs 45.67µs 21482. 1.48KB 2.1520.3.2 Mettre le minimum d’opérations dans les boucles
Si vous utilisez une boucle, toute opération qu’elle contient, comme elle va être répétée, peut devenir rapidement très coûteuse. Il ne faut donc y mettre que les opérations réellement nécessaires.
La fonction suivante prend en entrée un tableau de données d et une chaîne de caractères chr, et retourne un vecteur nommé indiquant le nombre de fois ou cette valeur apparaît dans chaque colonne du tableau. On a décidé de convertir en minuscules à la fois la valeur de chr et l’ensemble des colonnes du tableau pour que le comptage ne prenne pas en compte les différences de majuscules/minuscules.
nb_chaine1 <- function(d, chr) {
res <- numeric()
for (var in names(d)) {
# Conversion de chr et des colonnes de d en minuscules
d <- d %>% modify(str_to_lower)
chr <- str_to_lower(chr)
# Comptage des occurrences de chr dans la colonne var
res[[var]] <- sum(d[[var]] == chr, na.rm = TRUE)
}
res
}
d <- hdv2003[, c("hard.rock", "qualif", "clso", "bricol")]
nb_chaine1(d, "oui")
#> hard.rock qualif clso bricol
#> 14 0 936 853Ça fonctionne, mais si on regarde un peu plus attentivement le code de la fonction on peut vite se rendre compte d’un problème : les conversions en minuscules sont faites à l’intérieur de la boucle, et sont donc répétées pour chaque colonne de d. Or ceci n’est absolument pas nécessaire puisque cette conversion ne dépend pas des colonnes et qu’elle peut être faite une seule et unique fois en début de fonction.
On décide donc de sortir les conversions en minuscules de la boucle.
nb_chaine2 <- function(d, chr) {
res <- numeric()
# Conversion de chr et des colonnes de d en minuscules
d <- d %>% modify(str_to_lower)
chr <- str_to_lower(chr)
for (var in names(d)) {
# Comptage des occurrences de chr dans la colonne var
res[[var]] <- sum(d[[var]] == chr, na.rm = TRUE)
}
res
}
nb_chaine2(d, "oui")
#> hard.rock qualif clso bricol
#> 14 0 936 853Le résultat des deux fonctions est identique. On compare leur temps d’exécution à l’aide de bench::mark().
bench::mark(
nb_chaine1(d, "oui"),
nb_chaine2(d, "oui"),
)
#> # A tibble: 2 × 6
#> expression min median `itr/sec` mem_alloc `gc/sec`
#> <bch:expr> <bch:tm> <bch:tm> <dbl> <bch:byt> <dbl>
#> 1 "nb_chaine1(d, \"oui\")" 2.63ms 2.66ms 371. 345KB 0
#> 2 "nb_chaine2(d, \"oui\")" 751.95µs 774.38µs 1287. 157KB 2.02Ce qui permet de constater que la deuxième version est quatre fois plus rapide (et elle sera d’autant plus rapide que le nombre de colonnes du tableau sera grand).
20.3.3 Choisir un format de fichier adapté
Si on travaille sur des fichiers de données volumineux, les temps de chargement et de sauvegarde des données peuvent devenir importants.
Il existe différents formats de fichiers qui peuvont être plus ou moins rapides et pratiques selon l’utilisation qu’on en fait. Il n’est malheureusement pas toujours simple de s’y retrouver d’autant que les formats et les performances peuvent évoluer assez rapidement, mais on peut quand même donner quelques indications :
Le format CSV est pratique pour échanger des données tabulaires d’un système ou d’un logiciel à un autre, mais il présente plusieurs inconvénients :
- les fichiers sont volumineux
- les temps de lecture/écriture sont assez longs
- ils n’incluent pas de métadonnées comme les types des colonnes, et nécessitent donc des opérations de conversion plus ou moins “risquées”
À noter que plusieurs extensions et fonctions existent pour lire et/ou écrire les fichiers CSV. Outre read.csv de R base et read_csv de readr, on pourra mentionner fread de data.table, particulièrement rapide, ou l’extension vroom, qui ne charge pas toutes les informations d’un coup mais y accède “à la demande”.
Les formats Rdata (utilisé par load() et save()) et RDS (utilisé par readRDS() et saveRDS()), propres à R, permettent de sauvegarder des objets dans un fichier. Ils ont des temps de lecture et d’écriture rapides, et permettent d’enregistrer n’importe quel objet R et d’être sûr de le retrouver à peu près à l’identique. À noter que ces formats permettent de faire varier le niveau de compression des données et donc jouer sur le rapport entre espace disque utilisé et temps d’accès. Ces formats sont intéressants notamment pour enregistrer des résultats intermédiaires. À noter que le format fst, proposé par l’extension du même nom, offre des performances encore supérieures mais ne gère que les données tabulaires.
Pour des données vraiment volumineuses, le package arrow permet la lecture et l’enregistrement dans différents formats, dont arrow et parquet. Très optimisés mais limités aux données tabulaires, ils permettent également des échanges avec d’autres langages de programmation comme Python, JavaScript, etc.
À titre indicatif, le billet a shallow benchmark of R data frame export/import methods propose un comparatif entre les performances de différents formats de fichiers pour des données tabulaires. Attention cependant, il date de 2019 et les performances des fonctions testées ont pu évoluer depuis.
20.3.4 Repérer les opérations coûteuses avec du profiling
Quand on commence à écrire du code un peu long, il n’est pas toujours évident de savoir quelles sont les opérations qui sont les plus coûteuses en termes de performance. Il peut alors être utile d’utiliser un outil de profiling, qui consiste à exécuter du code tout en mesurant les temps d’exécution de chaque instruction, ce qui permet ensuite de visualiser et repérer les opérations qui prennent le plus de temps et qui seraient donc les plus intéressantes à optimiser (si c’est possible).
L’extension profvis fournit un outil de profiling sous R pratique et utile. On passe des instructions ou un script entier à la fonction profvis(), et celle-ci fournit une visualisation interactive des différentes opérations, de leur temps d’exécution, de leur utilisation de la mémoire…
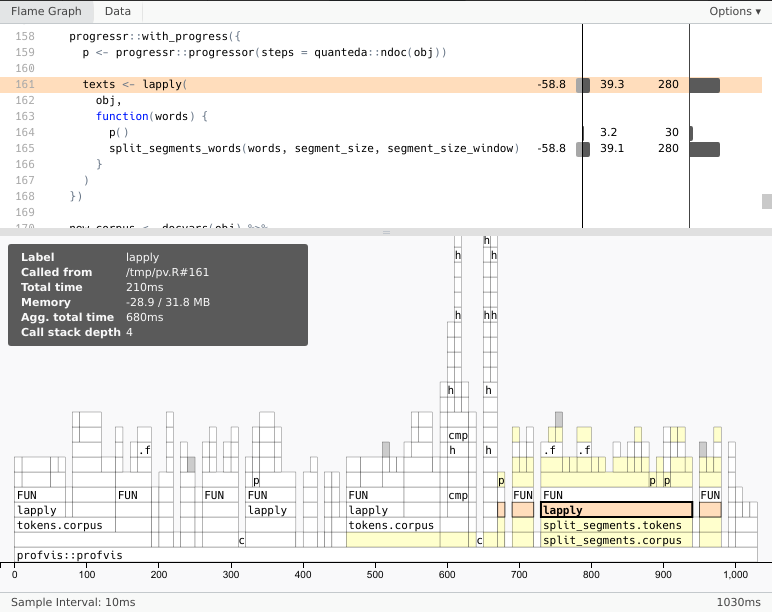
L’utilisation de profvis() dépasse le cadre de ce document, mais on pourra trouver des explications (en anglais) dans la partie profiling d’Advanced R.
20.3.5 Mettre en cache des résultats intermédiaires
Selon la taille des données et le type d’opérations réalisées, les temps de calculs même optimisés peuvent demeurer longs. Dans ce cas il peut être intéressant de “mettre en cache” des résultats intermédiaires dans des fichiers pour pouvoir les charger directement sans avoir à tout recalculer.
Par exemple, si on travaille sur un corpus de données textuelles, on peut enregistrer dans un fichier RDS ou Rdata le résultat de toutes les opérations de prétraitement du corpus : si on souhaite faire des analyses par la suite on aura juste à charger les données depuis ce fichier sans avoir à relancer le calcul de tous les prétraitements.
L’extension targets, présentée Chapitre 21, est particulièrement adaptée pour les projets de ce type car elle gère automatiquement les dépendances entre les étapes d’un projet et la mise en cache des résultats, et permet ainsi d’optimiser les temps de traitement.
20.3.6 Utiliser d’autres extensions
Enfin, si ce document est basé sur les extensions du tidyverse, qui offrent une syntaxe cohérente et plus facile d’accès, il existe d’autres extensions notamment dans le domaine de la manipulation des données qui permettent des opérations plus rapides.
C’est en particulier le cas de l’extension data.table, qui utilise une syntaxe moins accessible que celle de dplyr, mais propose des performances en général assez nettement supérieures. On trouvera la documentation détaillée de data.table (en anglais) sur le site de l’extension.
20.4 Ressources
L’ouvrage Advanced R (en anglais) consacre un chapitre entier au debuggage, un autre à la mesure de la performance, et un dernier à différentes techniques d’optimisation du code.
Le site de RStudio propose une page entière détaillant ses fonctionnalités de debugging (en anglais). Pour les utilisateurs de Visual Studio Code, on pourra se référer à l’extension VSCode-R-Debugger.