[en] Algorithms description
Julien Barnier
2026-05-05
Source:vignettes/algorithms_en.Rmd
algorithms_en.RmdThe goal of this document is to describe the algorithms used in the
rainette package and their implementation. This
implementation has been based upon two main resources :
- the three papers from Max Reinert cited in references (in french)
- the source code of Iramuteq,
especially the
CHD.Randchdtxt.Rfiles. Note however that the code has been almost entirely rewritten (in part in C++ via Rcpp).
Simple clustering algorithm
Document-term matrix
The simple clustering method is a divisive hierarchical clustering applied to a document-term matrix. This matrix is binary weighted, so only the absence or presence of a term in a document is taken into account.
Here is a sample matrix :
## return of the obra dinn
## doc1 1 1 1 1 1
## doc2 0 0 1 1 1
## doc3 1 1 1 0 0
## doc4 0 1 0 0 0Note that if documents are segments computed by
split_segments(), segments from the same source may be
merged together before clustering computation if some of them are too
short and don’t reach the minimum size given by the
min_segment_size argument of rainette().
Maximal χ² splitting
In the newt step, the goal is to split the document-term matrix into two groups of documents such as these are as “different” as possible. For the Reinert method, the “best” split is the one which maximizes the χ² value of the grouped array.
For example, using the previous matrix, if we group together
doc1 with doc2 and doc3 with
doc4, we get the following grouped array :
## return of the obra dinn
## doc1 + doc2 1 1 2 2 2
## doc3 + doc4 1 2 1 0 0We can compute the χ² statistics of this array, which can be seen has an association coefficient between the two document groups regarding their term distributions : if the χ² is high, the two groups are different, if it is low they can be considered as similar.
In such a simple case, we could compute every possible groupings and determine which one corresponds to the maximal χ² value, but with real data the complexity and needed computations rise very rapidly.
The Reinert method therefore proceeds the following way :
- we first compute a correspondance analysis on the document-term matrix, and we sort the documents along their coordinate on the first axis.
- we group documents together successively following this ordering : first the lowest coordinate document vs all the others, then the two lowest ones vs all the others, and so on. Each time we compute the χ² value of the grouped matrix, and we keep the grouping which corresponds to the highest χ² value.
- based on this grouping, we succesively assign each document to the other group, and see if this makes the χ² rise. If it is the case, the document is kept in the other group. This operation is repeated until no reassignment makes the χ² higher.
At the end we get two groups of documents and two corresponding document-term matrices.
Terms selection
The following step is to filter out some terms from each matrices before the next iteration :
- we compute each term frequency in both matrices, and remove terms
with a frequency lower than 3 (this value can be changed using the
tsjargument ofrainette()). - we also compare the observed frequency of each term and their
expected frequency under independance hypothesis of distribution between
the two groups. This allows to compute a contingency coefficient : if
this coefficient is higher than 0.3, the term is only kept in the matrix
where it is overrepresented (the 0.3 threshold can be changed using the
cc_testargument ofrainette()).
Divisive hierarchical clustering
The previous steps allow to split a documents corpus into two groups.
To get a hierarchy of groups, we first split the whole initial corpus,
then continue by splitting the biggest resulting cluster, ie
the one with the most documents (unless the cluster document-term matrix
is too small to compute a correspondance analysis, or if its size is
smaller than the value of the min_split_members argument of
rainette()).
By repeating this k - 1 times, we get a divisive
hierarchical clustering of k clusters, and the
corresponding dendrogram (the height of each dendrogram branch is given
by the χ² value of the corresponding split).
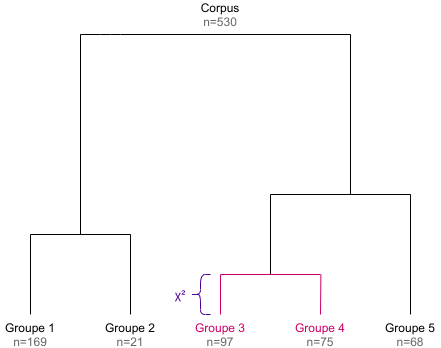
Double clustering algorithm
The double clustering only applies to a corpus which has been split into segments. The goal is to make clusters more robust by crossing the results of two single clusterings computed with different minimal segment sizes.
Doing a double clustering implies therefore implies that we first do
two simple clusterings with distinct min_segment_size
values. We then get two different dendrograms determining different
clusters, here numbered from 1 to 6 :

Cross-clusters computation
The first step of the algorithm is to cross all clusters from both dendrograms together :
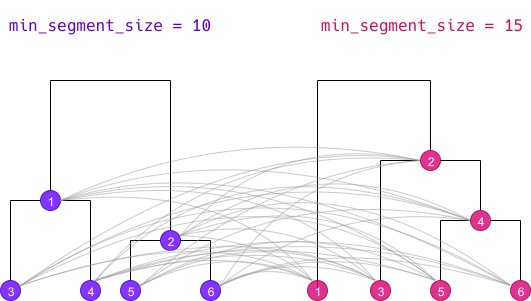
Each cluster of the first simple clustering is crossed with each
cluster of the second one, even if both cluster do not belong to the
same k level. The new resulting cluster is called a
“crossed cluster” :
- for each crossed cluster, we compute its size, ie the number of segments belonging to both clusters.
- using this size, the size of both clusters and the total number of segments, we can create a cross table of clusters membership : we compute the χ² value of this table, which can be seen as an “association coefficient” between the two clusters.
- if two different crossed clusters hold exactly the same segments, we only keep one.
- if a crossed cluster size is lower than the value of the
min_membersargument ofrainette2(), it is discarded. - if a crossed cluster has an association χ² lower than the value of
the
min_chi2argument ofrainette2(), it is discarded.
| Crossed cluster | Size | Association χ² |
|---|---|---|
| 11 | 25 | 41.2 |
| 12 | 102 | 30.1 |
| 13 | 59 | 87.3 |
| 14 | 41 | 94.0 |
| 15 | 0 | - |
| 16 | 13 | 6.2 |
| 21 | 0 | - |
| … | … | … |
| 66 | 5 | 3.1 |
Once these crossed clusters have been computed, two types of analysis are possible.
“full” analysis
The first type, called a “full” analysis (full = TRUE
argument of rainette2()), retains for the following steps
all the crossed clusters with a size greater than zero (if these have
not already been filtered out at the previous step). In the previous
example, we would keep :
| Crossed cluster | Size | Association χ² |
|---|---|---|
| 11 | 25 | 41.2 |
| 12 | 102 | 30.1 |
| 13 | 59 | 87.3 |
| 14 | 41 | 94.0 |
| 16 | 13 | 6.2 |
| … | … | … |
| 66 | 5 | 3.1 |
“classical” analysis
The second type, called a “classical” analysis
(full = FALSE argument of rainette2()), only
keeps for the following steps the crossed clusters whose clusters are
mutually most associated. Thus, if we consider the crossed cluster
crossing cluster x and cluster y, we only keep this
crossed cluster if y is the cluster with the highest
association χ² with x, and if at the same time x is
the cluster with the highest association χ² with y.
In this case the number of crossed clusters kept for the following steps is much lower :
| Crossed cluster | Size | Association χ² |
|---|---|---|
| 14 | 41 | 94.0 |
| 33 | 18 | 70.1 |
| 46 | 21 | 58.2 |
| 65 | 25 | 61.0 |
Determining optimal partitions
The goal of the next step is to identify, starting from the set of crossed clusters defined previously, every possible partitions of our corpus in 2, 3, 4… crossed clusters. More precisely, we try to identify each set of 2, 3, 4… crossed clusters which have no common elements.
We start by computing the size 2 partitions, ie every set of 2 crossed clusters without common elements. For each partition we compute is total size and the sum of its association χ².
| Partition | Total size | Sum of association χ² |
|---|---|---|
| 11 23 | 47 | 62.3 |
| 14 35 | 36 | 51.0 |
| 24 16 | 29 | 38.2 |
| 12 53 | 143 | 68.7 |
| … | … | … |
We only keep among these partitions the ones that are considered the “best” ones :
- if we are doing a “full” analysis (
full = TRUE), we keep the one having the highest sum of χ², and the one with the highest total size. - if we are doing a “classical” analysis (
full = FALSE), we only keep the one with the highest sum of χ² (we can use the highest total size criterion in this case).
| Partition | Total size | Sum of association χ² |
|---|---|---|
| 12 53 | 143 | 68.7 |
| 34 26 | 86 | 98.0 |
We do the same for the size 3 partitions : we identify every set of 3 non overlapping crossed clusters, and keep the “best” ones.
| Partition | Total size | Sum of association χ² |
|---|---|---|
| 12 53 25 | 189 | 91.3 |
| 34 26 53 | 113 | 108.1 |
And we repeat the operation for 4 crossed clusters, etc.
| Partition | Total size | Sum of association χ² |
|---|---|---|
| 34265315 | 223 | 114.7 |
The operation is repeated until we reach the value of the
max_k argument passed to rainette2(), or until
there is no possible partition of the size k.
Result
At the end we get, for each k value from 2 to
max_k, a selection of the “best” crossed clusters
partitions, either according to the association χ² criterion or
according to the total size criterion. These crossed clusters form a new
set of clusters which are potentially more “robust” than the ones
computed from the two simple clusterings.
After this operation, a potentially high number of segments may not
belong to any cluster anymore. rainette allows to reassign
them to the new clusters with a fast k-nearest neighbours
method, but this may not be recommended as we would then loose the
clusters robustness acquired with the double clustering.
Differences with the “Reinert method”
The way to determine the optimal partitions did not seem completely
clear to us in the articles cited in references, so it is not really possible to
compare with the rainette implementation. The “classical”
method described in this document seems to be close from the one
suggested by Max Reinert : after computing the crossed clusters, we only
keep the ones where the two crossed clusters are both the most mutually
associated.
One important difference is the fact that once the best partition of
crossed clusters has been determined, Max Reinert suggests to use these
new groups as starting points to reassign the documents to new clusters
with a k-means type method. This is not implemented in
rainette : the rainette2_complete_groups()
allows to reassign documents without cluster using a k-nearest
neighbours method, but this may not be recommended if you want to
keep the “robustness” of the clusters computed with the double
clustering.
References
- Reinert M., “Une méthode de classification descendante hiérarchique : application à l’analyse lexicale par contexte”, Cahiers de l’analyse des données, Volume 8, Numéro 2, 1983. https://www.numdam.org/item/?id=CAD_1983__8_2_187_0
- Reinert M., “Alceste une méthodologie d’analyse des données textuelles et une application: Aurelia De Gerard De Nerval”, Bulletin de Méthodologie Sociologique, Volume 26, Numéro 1, 1990. https://doi.org/10.1177/075910639002600103
- Reinert M., “Une méthode de classification des énoncés d’un corpus présentée à l’aide d’une application”, Les cahiers de l’analyse des données, Tome 15, Numéro 1, 1990. https://www.numdam.org/item/?id=CAD_1990__15_1_21_0